Projects
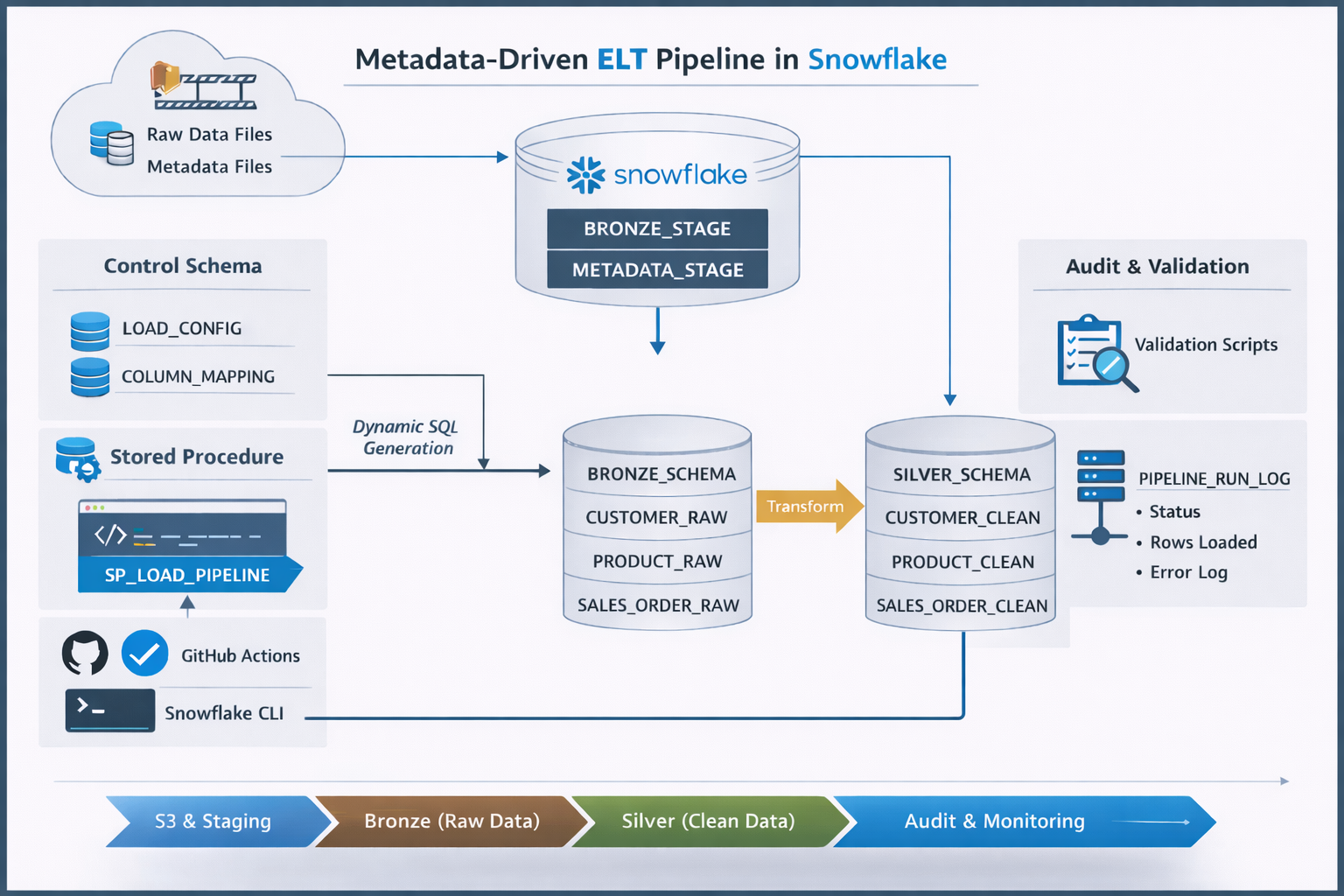
Metadata-Driven ELT Pipeline in Snowflake
Designed and implemented a scalable metadata-driven ELT pipeline using Snowflake, Amazon S3, and GitHub Actions. Built a reusable stored procedure to dynamically generate SQL based on configuration tables, enabling onboarding of new pipelines without code changes. Implemented Bronze-to-Silver transformations, audit logging for pipeline observability, and CI/CD automation for deployment and execution.
Technologies: Snowflake, SQL (Snowflake Scripting), Amazon S3, GitHub Actions, Snowflake CLI, Data Engineering
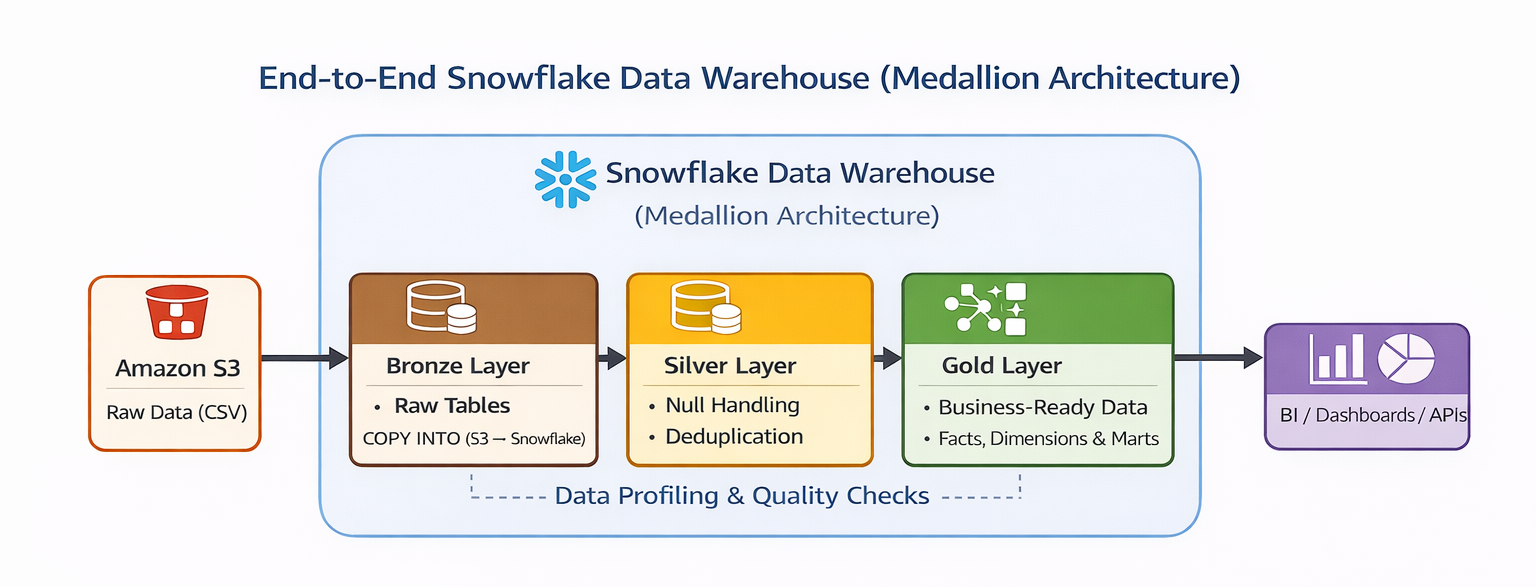
End-to-End Snowflake Data Warehouse (Medallion Architecture)
Designed and implemented a production-style data warehouse using Snowflake following the Medallion Architecture (Bronze, Silver, Gold). Built secure ingestion from Amazon S3, performed data profiling and transformation, and developed a star schema with fact and dimension tables along with business-ready marts for analytics.
Technologies: Snowflake, SQL, Amazon S3, Data Warehousing, Medallion Architecture
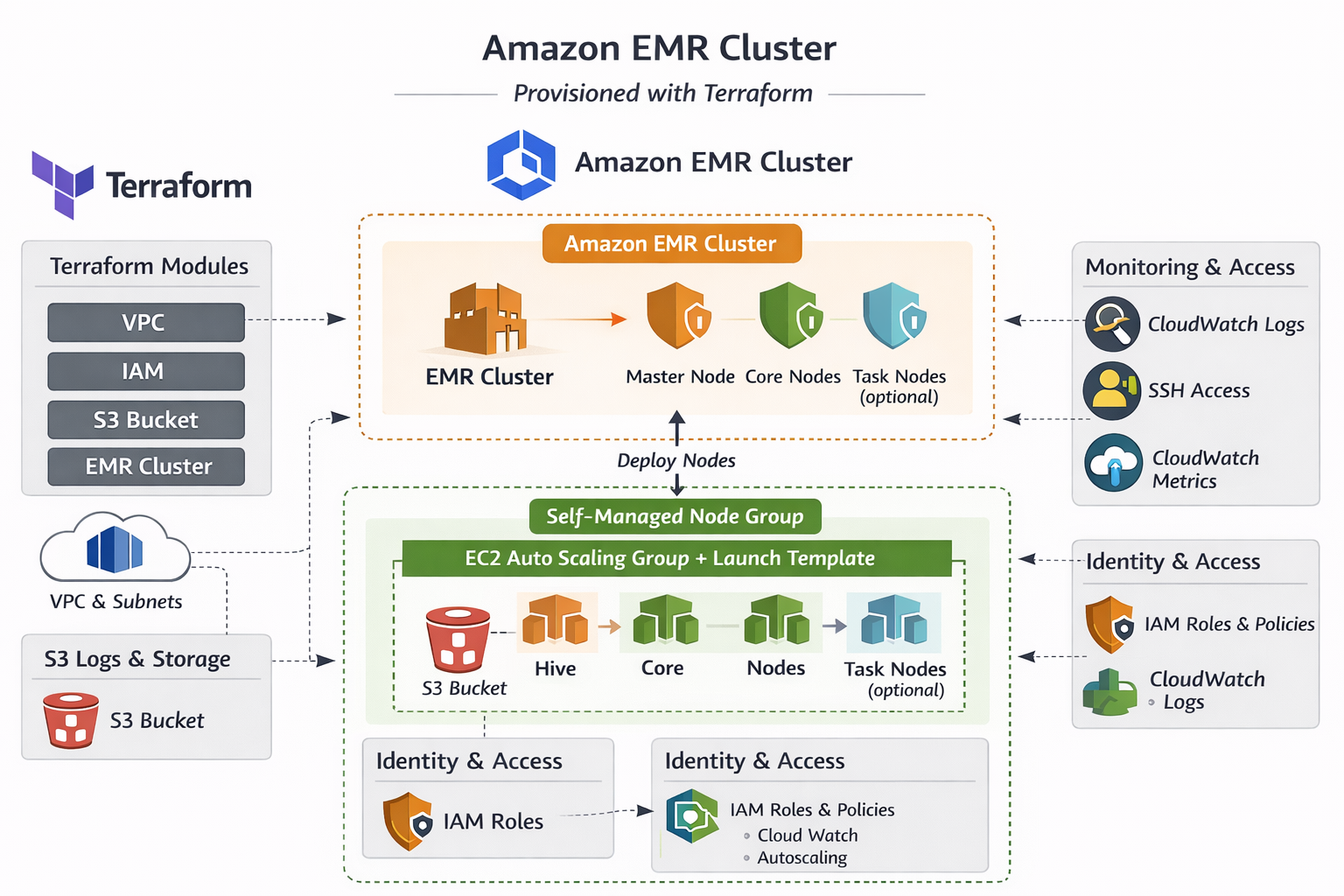
Provisioning an AWS EMR Cluster using Terraform
Automated the setup of an Amazon EMR cluster for big data processing using Apache Spark and Hadoop. Used AWS CLI and Python (Boto3) to provision resources, integrate with S3, and optimize for cost and scalability.
Technologies: AWS EMR, Apache Spark, Hadoop, Python (Boto3), AWS CLI, S3
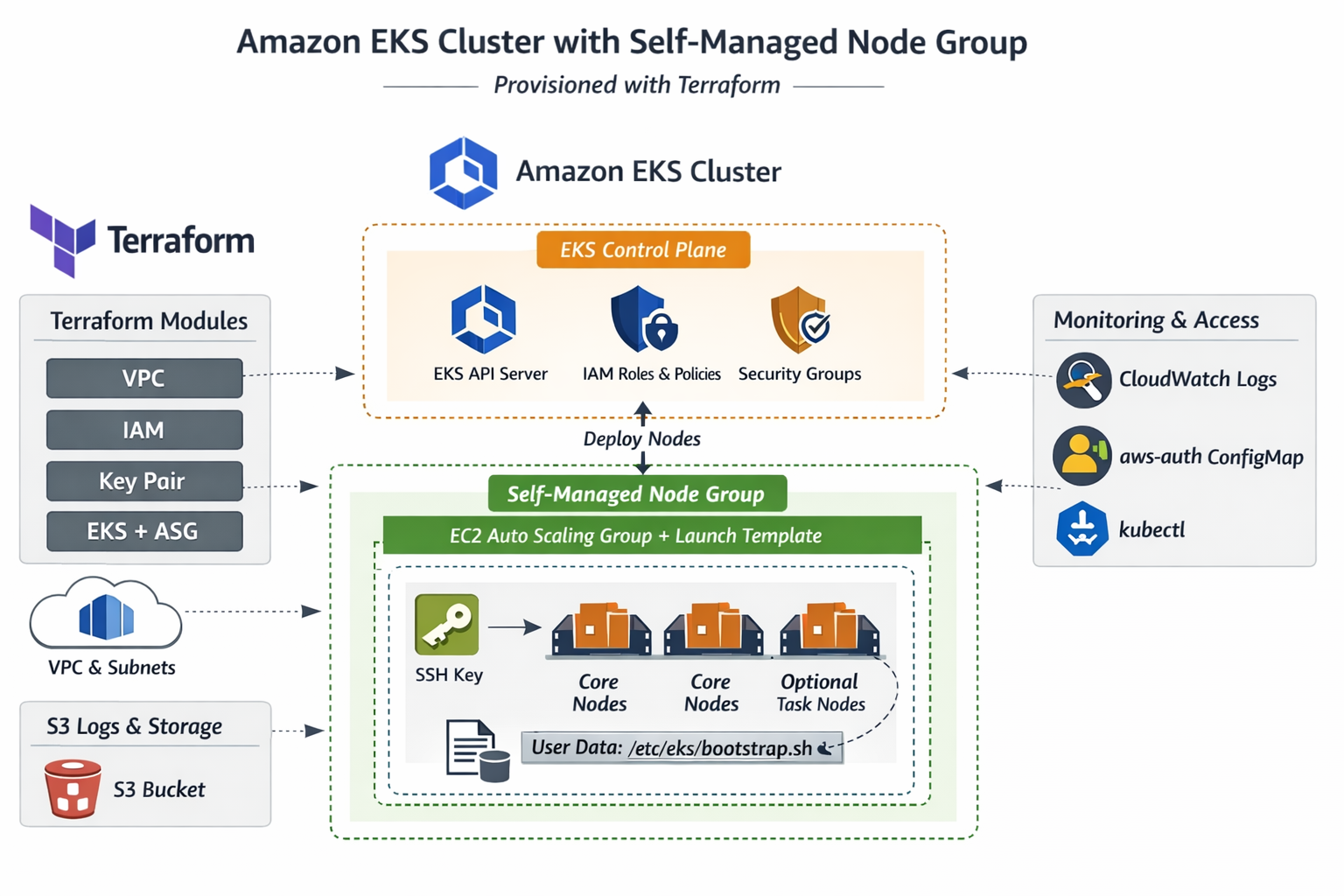
Provisioning EKS with Self-Managed Node Groups using Terraform
Automates the deployment of Amazon EKS clusters with self-managed node groups using Terraform. Enables scalable, customizable Kubernetes infrastructure with full control over worker nodes.
Technologies: Terraform, AWS EKS, Kubernetes, IAM
Personal Portfolio Website
A responsive, modern portfolio website showcasing my experience, projects, certifications, and contact information. Built with a focus on clean UI, accessibility, and performance, and deployed with CI/CD on Netlify.
Technologies: HTML, CSS, JavaScript, Netlify, Formspree